Data science has become, in my opinion, the biggest thing since accounting, for a business/organization. Last month, we looked at the basics of data science and how to understand it. In this post, we take a look at an important aspect of data science, predictive analytics focusing on machine learning and AI.
Predictive analytics includes a diverse set of techniques to use historic and current data. It finds patterns in that data which can be useful in making a point about some future state. Predictive analytics can be used in predicting defaults on loans or the amount of damage caused by a disaster. Machine learning has assumed the top spot in fulfilling those predictive ambitions, seeing an explosive increase in usage.
How does Machine Learning Work
Machine learning is a means of teaching computers to accomplish tasks by learning from many examples, without explicitly programming them. When a computer is given a task, and some performance measure on the task can be improved by the computer’s experience on the task, then it is said to be learning. Machine learning is a subset of artificial intelligence (AI). Here we are trying to get computers to imitate human faculties be it vision, language, sensing, movement, etc.
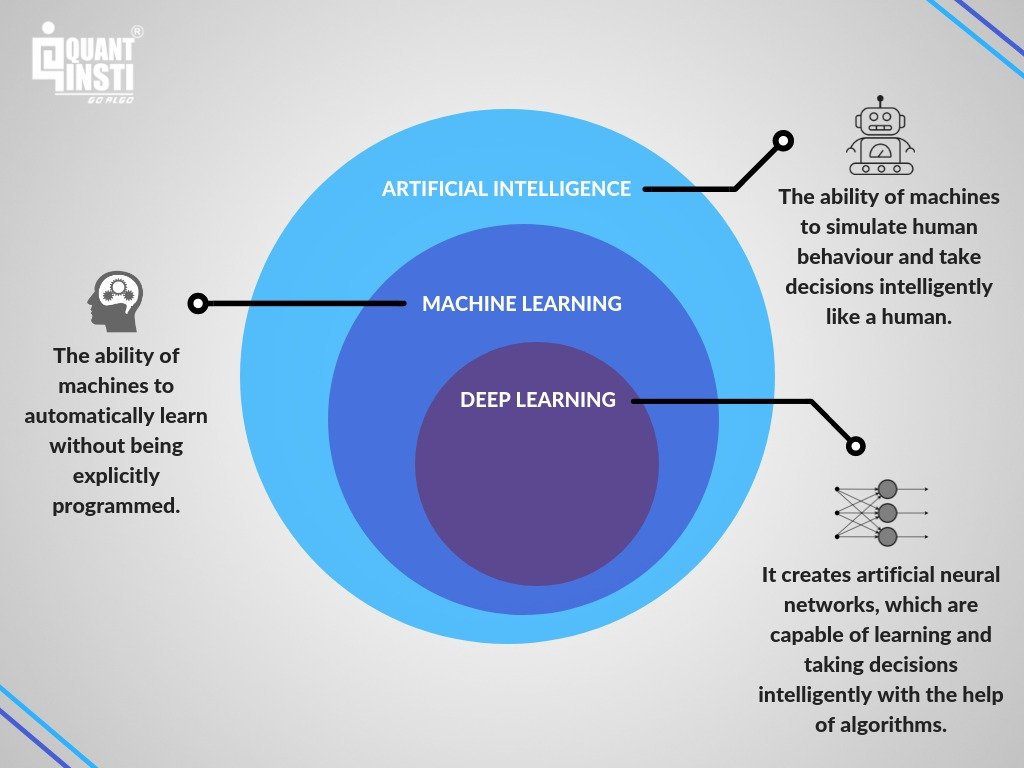
A simple break down of machine learning
Machine learning is broadly divided into three categories. Namely, supervised, unsupervised, and reinforcement learning. These categories are defined by how learning is done. Imagine a box, which we feed inputs, and produce outputs. There can be levers/switches/buttons, inside and outside the box. These can be fiddled with to affect the quality of outputs.
Supervised Learning
Supervised learning takes place when a computer is given both the inputs and the outputs to complete a task. It is then asked to figure out how to best match the given inputs to the outputs. As it goes through this, it analyses parameters that reflect the relationship between the inputs and outputs. For example, getting all the information about sold houses in a neighbourhood or town. The inputs would be the attributes of the house (number of bedrooms, year built, price). The price is the target to be predicted. After learning the relationships governing the attributes and the price, a scenario (or instance) of the houses data will be offered. The model can make a prediction on the price given the characteristics of the house.
Unsupervised Learning
Unsupervised learning means that we do not have the outputs to train the model. So the machine has to find latent relationships by just looking at the inputs by themselves. Using the above example, the model is not given the prices of the houses. The idea is to come up with representations that could discern between houses of different characteristics. The model groups the instances of data. From there it can determine under which group a new instance a house might fall. Unsupervised learning is more useful with classification. Discrete groupings are the output of the learning (There is a possibility of regression here).
Reinforcement Learning
Reinforcement learning (RL) gives an interestingly different approach. It uses foundations in diverse fields like psychology, optimization, operations research, economics, mathematics. In this category, training is done by providing incentives/rewards for doing the right thing, and punishments for the wrong action. In RL, we have an environment, where actions taken alter the environment. Agents taking action have a reward function for taking particular actions. The agent learns which actions to take, in order effort to maximize its reward returns to reach a certain goal. RL has been used to conquer games like Chess and Go. These are multi-strategy, multi-state problems which were considered beyond machine capabilities.
However, it would be remiss to not mention deep learning in this discussion. Deep learning (DL) is a subset of machine learning, in which layers of neural networks make up the learning model. DL has been way more practical in solving problems of computer vision and natural language processing. It has given rise to self-driving cars, virtual assistants like Alexa and Cortana, and Google translation services. Machine learning techniques require manual feature engineering. This ensures that the inputs to the model give the best chances of discovering the patterns in the data. DL manages to pick out the features automatically. This is what makes it perfect for the problems that it has worked on.
Machine learning and AI are thus very much applicable to many aspects of any organization’s operations. From predicting customer churn to more advanced applications like detecting fake images and language translation. It would make for a great skillset in an organization’s arsenal.

Leonard Mutambanengwe
Leonard Mutambanengwe is a Convener at Data Science Zimbabwe, an organization creating platforms for the embracing of data science, machine learning and artificial intelligence and the establishing of collaborative networks and linkages in Zimbabwe. He is interested in Computational Social Science and Decision Intelligence; the leveraging of big data techniques including DS, ML and AI, to social sciences particularly Economics. He is passionate about advocating for the creation of unique solutions to Zimbabwean and African opportunities.
He can be be contacted at @LeoLENNY1 on Twitter or Leonard Winter Mutambanengwe on LinkedIn.